OBJETIVOS
Desarrollar sistemas de clasificación que permitan la desambiguación de tweets sobre criptomonedas y empresas bursátiles con el mismo cashtag.
Diseñar clasificadores heurísticos basados en el conocimiento del dataset mediante su análisis explorativo.
Implementar y entrenar sistemas estadísticos de clasificación.
Combinar el funcionamiento de los sistemas anteriores para mejorar sus prestaciones.
Influencia de las Criptomonedas en tweets
con Cashtags del LSE
REGRESIÓN LOGÍSTICA
SVM
REDES NEURONALES
HEURÍSTICOS
R
PYTHON
KERAS
LSE
CASHTAG
METODOLOGÍA
Análisis exploratorio detallado de los datos para la identificación de elementos potencialmente relevantes
Diseño de filtros heurísticos basados en características y términos discriminantes
Implementación sobre R de modelos de regresión logística y máquinas de vectores soporte
Desarrollo sobre Python empleando Keras de redes neuronales para la clasificación de los tweets
Combinación de los filtros heurísticos con los clasificadores estadísticos
INTRODUCCIÓN
La inclusión de la tecnología en los mercados financieros ha llevado a un continuo crecimiento en su negocio. Estas nuevas tecnologías ayudan tanto a las grandes compañías como a los inversores particulares a obtener información sobre diferentes temas de interés como serían la situación de una empresa, la opinión de los clientes, noticias sobre cambios significativos, rumores… A medida que las redes sociales han invadidos los hábitos de la gente, también las compañías, brokers y otros papeles clave en el mercado financiero empezaron a publicar en este tipo de redes más y más información de utilidad y opiniones profesionales sobre las bolsas de valores. Toda esta información disponible de forma pública vuelve las redes sociales, especialmente Twitter, en una de las mayores, si no la mayor, fuente de información para brokers e inversores particulares.
Uno de los principales mecanismos proporcionados por Twitter para rastrear la información financiera sobre una compañía bursátil es el cashtag, una etiqueta formada por el acrónimo de una compañía precedida por el símbolo $. Esta etiqueta se agrega a los tweets, de manera similar a lo que sucede con los hashtags, e indica que contiene información financiera sobre la compañía a la que hace referencia el ticker. Todo esto vuelve a los cashtags uno de los mecanismos más útiles para recolectar fácilmente información financiera en Twitter.
Sin embargo, la irrupción de las criptomonedas en los últimos meses ha producido una degradación en la calidad de la información obtenida a través de este recurso. Esto se debe al hecho de que algunas de estas tienen tickers homónimos a los de algunas de las compañías de los principales mercados, es decir, algunas criptomonedas tienen el mismo ticker que algunas compañías bursátiles, en gran parte debido a la gran cantidad y falta de regulación de las primeras. Como resultado, cuando se usa un cashtag, se obtienen resultados que se refieren tanto a compañías bursátiles como a criptomonedas. Esto, sumado a la baja calidad de los tweets acerca de criptomonedas, la mayoría de ellos mensajes de spam o generados automáticamente por máquinas, produce una degradación muy significativa en la capacidad informativa de este recurso.
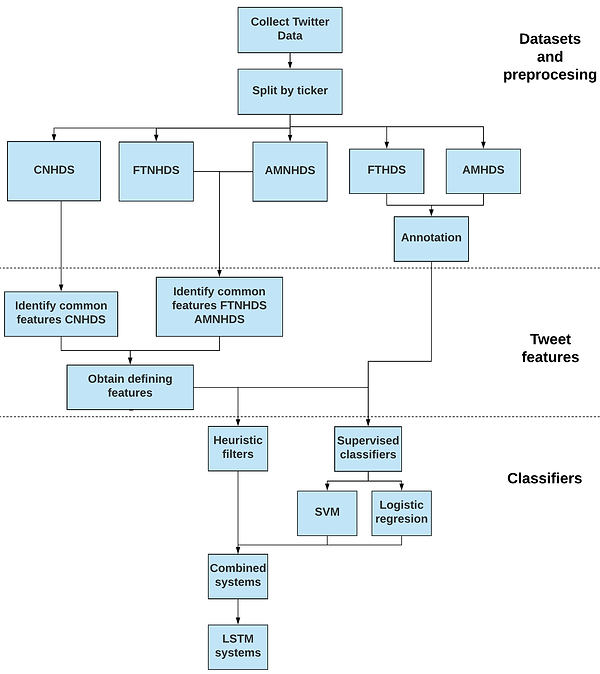
Así, el objetivo de este proyecto es implementar una serie de mecanismos de desambiguación que permitan distinguir entre ambos tipos de tweets, aunque estos compartan el mismo cashtag. Más concretamente, se desarrollarán diferentes sistemas estadísticos de clasificación que nos permitan diferenciar ambos tipos. Junto con estos se propondrán una serie de filtros heurísticos a partir de las características distintivas vistas durante el análisis descriptivo. Finalmente, se combinarán ambas alternativas estos filtros con los sistemas estadísticos de clasificación anteriores para mejorar su rendimiento.
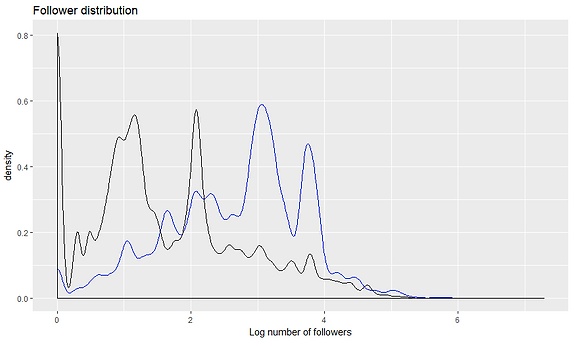
Para ello se dispone de un total de 326.354 tweets que contienen cashtags que pueden referirse tanto a una empresa de la bolsa de valores de Londres (LSE) como a una criptomoneda. Estos han sido manualmente clasificados, identificando si tratan de una compañía bursátil o no. Además de ellos, para realizar el análisis descriptivo e identificar las características distintivas entre ambos tipos, se dispone de un total de 1.562.495 tweets con cashtags de criptomonedas y empresas bursátiles no coincidentes. El contenido de estos tweets ha sido previamente preprocesado y adaptado a una representación fácilmente interpretable por máquinas mediante el uso de técnicas de NLP y su conversión a un vector empleando una matriz de word embeddings.
DESARROLLO
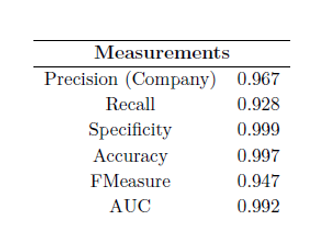
Para la definición de los filtros heurísticos se ha realizado un análisis descriptivo pormenorizado buscando las características distintivas entre los tweets sobre criptomonedas y compañías bursátiles. En base a estas, se han implementado sobre Python un conjunto de sistemas de clasificación heurísticos ajustados para descartar la mayor cantidad posible de tweets sobre criptomonedas perdiendo en el proceso la menor cantidad de tweets con información bursátil, o en otras palabras entrenados para maximizar la precisión mientras mantienen el recall por encima de un cierto límite.
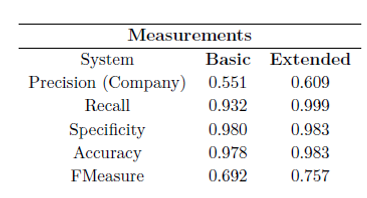
Adicionalmente se han desarrollado sistemas de clasificación combinados, que emplean la salida de los filtros heurísticos como una nueva entrada para los modelos estadísticos de clasificación. De esta manera, estos últimos pueden realizar una separación más fina gracias al filtrado inicial de los heurísticos.
Asimismo, en base al conocimiento adquirido durante la clasificación manual y el análisis descriptivo se han planteado modificaciones en las variables introducidas a estos sistemas para adecuarlas a las características concretas de las empresas coincidentes de la bolsa londinense, mejorando su rendimiento para estas pero degradándolo para empresas no estudiadas pertenecientes a otros mercados.
Como resultado de este proyecto se han obtenido un abanico de sistemas capaces de distinguir entre los tweets referentes a criptomonedas y a empresas bursátiles con un error muy reducido. Estos sistemas combinarían clasificadores estadísticos con filtros heurísticos diseñados específicamente para esta tarea para lograr una mejor separación entre ambos tipos. Dentro de estos se han propuesto diferentes alternativas dependiendo de las restricciones computacionales que se tienen y el ámbito de aplicación que se busque.
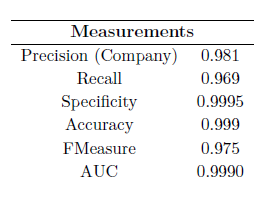
RESULTADOS

Para la distinción entre estos tipos de tweets se han propuesto varios sistemas estadísticos de clasificación. En particular, se han desarrollado sobre R distintas alternativas de modelos de regresión logística y máquinas de vectores soporte. Junto con estos, también se han implementado distintas topologías de red neuronal, programadas estas sobre Python empleando como apoyo la librería Keras.
Estos modelos emplean como variables de entrada tanto los propios parámetros del tweet y el usuario que lo postea como el contenido del mismo, este último tanto en forma de presencia de ciertos términos clave como mediante su transformación a un vector mediante una matriz de word embeddings. Distintas combinaciones de estas han sido consideradas dependiendo de sus restricciones computacionales, el tiempo de vida del sistema resultante y el compromiso entre precisión y recall buscado.